The database to be presented in this paper is our main tool for the production of a series of specialist SL dictionaries we have been working on since about ten years. Currently, the fifth dictionary (home economics) is on its way, following computer terminology, linguistics, psychology, and joinery. Starting with the psychology dictionary, we use an empirical approach, i.e. the dictionaries are based on a corpus. Signs were collected from deaf specialists in those fields by elicitation and guided interviews.
The concepts the dictionaries cover are selected by educators in the special fields, an approximate number of entries is given to them as an external (budget) restriction. Their selection is based on importance for the field as well as on curricula as one of the targets of these dictionaries is to ease the way to equal access for Deaf people to education by bringing their language into the education process.
Our first step in the production of a dictionary is to find informants, i.e. Deaf people using SL as their primary language and at the same time being specialists in the field to be covered as they might have studied the matter or passed a professional education or have been working in the area for some time. In choosing among the candidates found we try to cover as many regions in Germany as possible.
Starting with a list of concepts to go into the dictionary, we prepare material for eliciting signs. Currently, we use three techniques: guided interviews, presentation of pictures (photographs, diagrams etc.), presentation of spoken language words. In single-informant sessions, we record the informants' signing on digital videotape. The tapes are transferred later onto computer storage media (DVDs).
The analysis of the video data collected is then done on computers by a team of up to a dozen persons, both Deaf and hearing. The transcription and analysis process results, for each concept to be covered, in a heavily annotated list of signs used by the Deaf informants. This list then forms the basis for the decisions what signs to include in the dictionary.
The database currently in use is the third generation. We started with some FileMaker databases for the psychology dictionary. As it turned out very difficult to guarantee SL domain-specific consistency rules in a general purpose database, we developped a custom application for the next project. While this solved some consistency problems, the program was not flexible enough to match our ever-changing demands and too slow to support a dozen of concurrent users. Furthermore, it lacked real integration of video.
We therefore set up an SQL database server and developed a custom front-end tightly integrating digital video: GlossLexer II.
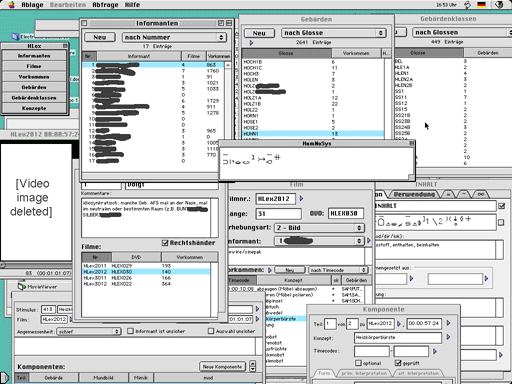
Starting from a floating window for accessing all the available lists, the user can open any number of windows. Double-clicking in lists or clicking on the triangles near to related information opens a new window detailing this information.
The following description is broken down into chapters each dealing with one table in the database structure as these are closely related to the windows in the front-end program
.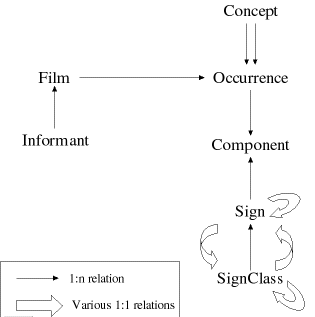
Occurrences are the responses to concept elicitations. They consist of one or more signs uttered (as the informant might answer with more than one sign or a description. This means that in the first step of analysis we do not differentiate between sequential compounds and phrases.). The parts of these utterances are referred to as components. Occurrences are recorded on films, and our video footage has been chunked in a way that each film covers a (partial) session with only one informant.
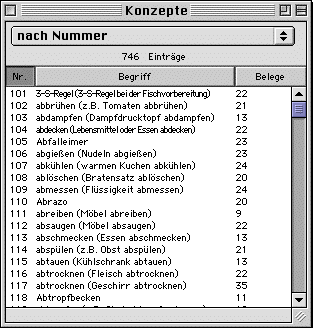
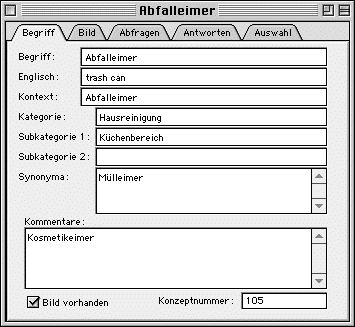

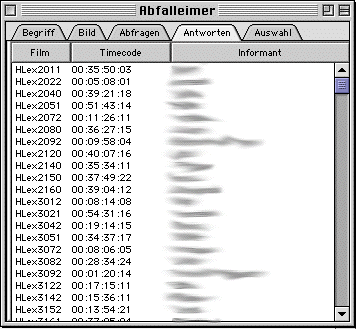
The concepts window ("Konzepte") window lists all concepts in the project database by giving their number, spoken language term, and the number of occurrences for each concept. By using the pop-up menu, the user can restrict the list to only those matching certain criteria or change the order the concepts are listed in. An example of restrictions implemented is concepts with no responses.
More restrictions can be added simply by inserting a record into the queries table of the database. This means that program behaviour can be expanded without updating the program itself, which turns out to save some time in a multi-user environment.
[In the screen dumps above and below you find some elements used for the decision process on what signs go into the final dictionaries (cf. selection tab ("Auswahl") in the concept window ("Konzept")). These are not presented in detail in this article as they only offer additional tagging capabilities and therefore do not contribute to the lexical database structure per se.]
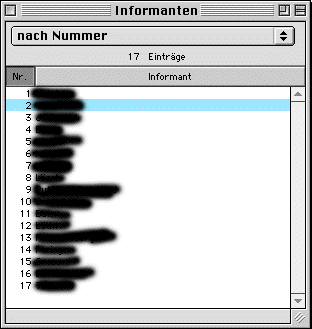
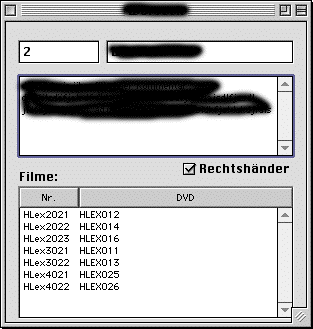
For the informants, only minimal information is contained in the database, namely the name (and identifying number), a comments field as well as information whether the person is right- oder left-handed. Personal and sociographic data for each informant are separately documented on video and on a questionnaire. Information relevant for the transcription and analysis such as regional variation is given as free text in the comments fields). (Keep in mind that access to the databases is currently handled on a need-to-know basis, no person from outside the dictionary projects can view the data.)
In addition to data on the informant, the "Informant" window lists all films that have been recorded for this informant, giving direct access to the respective film window ("Film").
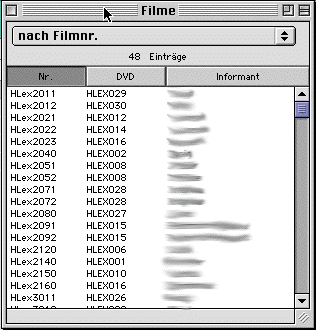
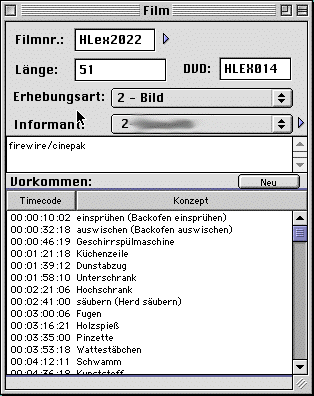
Opening the films window ("Filme") lists all the film records in the database. By using the pop-up menu in the upper part of the window, you can determine what selection of films in which order you want to see. Double-clicking on one of the entries opens a detail window for that film ("Film"). It gives information regarding the film as well as the elicitation technique (picture or text) and the informant and provides a comments field.
The QuickTime movie described by this this record is not itself stored in the database as the data size of the movies belonging to a project is huge (for the current project: 150 GB). Instead, we store them in files in two different formats: A near-fullsize version of each film is available on Digital Versatile Disc (DVD), and there a two copies of each disc available. People working mainly on one film, e.g. when doing the first transcription of one informant's responses need the near-fullsize version on DVD, especially for the documentation of mouthing. If the DVD is not inserted in the user's DVD drive, the program falls back to a quarter-size movie stored on our central file-server. This size of video is more than enough to check transcriptions or to compare different instantiations of signs.
Clicking into the triangle right to the name of the film (in the screen shot, the film name is HLex2022, signalising that it belongs to the HLEX (home economics dictionary project) opens the QuickTime movie.
In the lower part, you find a list of all occurrences in this film. Double-clicking on one of these opens the corresponding window. This is also the only place in the program from where to enter new occurrences into the database since occurrences must belong to a film.
The occurrences window ("Vorkommen") gives you access to occurrences matching certain criteria, e.g. those occurrences whose appropriateness still needs to be decided upon. Due to the potentially very large number of occurrences within a project (about 12500 in the current project), it makes no sense to have a list of all occurrences available. Rather, you would view all those occurrences fitting into a certain context such as those belonging to one film (read: one elicitiation kind for one informant).
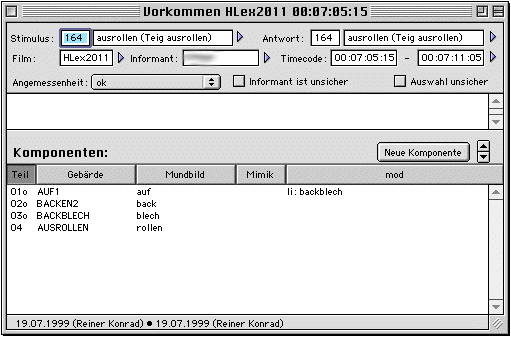
Double-clicking on one occurrence results in a detail window ("Vorkommen HLex …") to be opened which gives context information for the occurrence as well as comments and cagetorisation regarding the appropriateness of the response given.
Each occurrence is identified by the film it is contained in as well as its timecodes on that film. It shows the concept that was the elicitation target ("Stimulus"). In some cases, the response conveys the meaning of another concept contained in the concepts list. Therefore, the transcriber can specifiy another concept in a second field ("Antwort). E.g., this may be due to ambiguous photographs, or near-homography in the elicitation via spoken language words. The transcriber also decides whether the informant gave an appropriate answer at all and whether the informant was unsure about what to answer. (The latter may help in deciding on the first.) In the first analysis steps, the transcribers can choose between "appropriate", "inappropriate" and "yet to be decided", where the last category flows into a work-list to be checked by other transcribers. Occurrences marked as inappropriate need not be transcribed, but are easily accessible by film number, timecode, and concept. In later analysis steps, any inappropriate occurrences are simply ignored.
Finally, the window lists the components belonging to this occurrence. These are the signs forming the response, here identified by the gloss as well as mouthing and facial expression plus some on meaningful modifications.
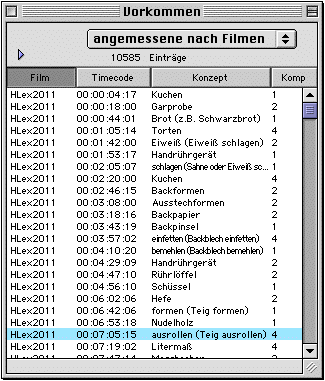
It is not the regular case that occurrence entries are created by the transcribers during the transcription process. Instead, the films are pre-segmented using the syncWRITER program as this program's user interface makes segmenting quite an easy process. After data collection, this is the first step of analysis, where data are reviewed and can also already be marked as inappropriate if necessary. The syncWRITER documents are then imported into the database resulting in "empty" occurrences that need to be filled by the transcribers. Of course, any segmentation decision taken in the pre-process can be revised directly in GlossLexer without the need to go back to syncWRITER.
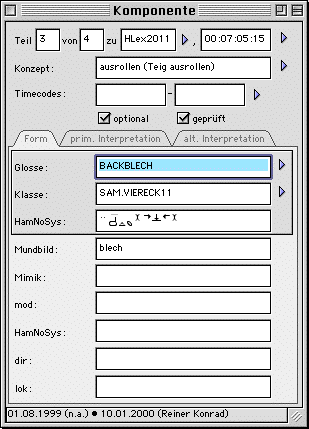
A component is a sign uttered as part of an occurrence (a sequence of signs). An "empty" occurrence as mentioned above is one that has no components. When adding a component to an occurrence ("Neue Komponente" in the occurrence window), a new component window ("Komponente") opens. The transcriber needs to determine which sign this component consists of as well as to describe the mouthing ("Mundbild") and facial expression ("Mimik"). For choosing the appropriate sign, the program can assist the user by suggesting all signs whose glosses share a number of initial characters and by showing the HamNoSys notation for each sign in the suggestion list.
Moreover, if the utterance is not identical with the sign's citation form, the modification needs to be described in terms of HamNoSys and written text using different categories, such as modification of meaning, direction and location.
By binding mouthing and facial expression to the component, we do not allow for notating phenonema spanning more than one component as we do not consider this essential in the context of lexical analysis.
The timecode fields for the components need not be filled. If, however, they are, the program is able to extract the video for just one component from the occurrence. This is particularly useful if you need to see video representations of the the signs in the database. We therefore fill out the timecode fields for at least one usage of each sign in the database. Once again, there is a special work-list showing occurrences whose components need timecoding.
As in the other windows, you find a number of triangles allowing you to follow the hyperlinks, e.g. to see the sign entry, the video, or concept info.
The signs list ("Gebärden") certainly is the heart of the database. Most of the analysis work consists of building and annotating this list.
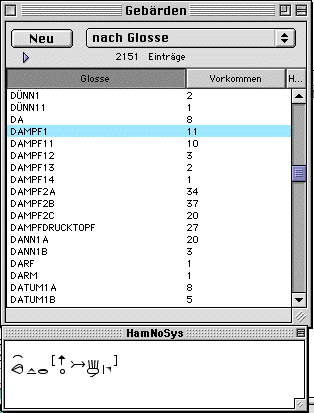
The result of our transcription is a lexical analysis of the signs in our corpus. Therefore, we try to relate occurrences of signs (tokens) in a consistent way to signs (types). Our transcription conventions allow to code many relevant features of signs into the gloss: Glosses have different prefixes, e.g. $MAN (manual activitiy, labelling productive signs), $ALPHA for usages of manual alphabets, and suffixes. Number suffixes distinguish different signs with the same meaning, but different underlying images (e.g. DAMPF1 vs. DAMPF2) as well as meaningful modifications (e.g. DAMPF11 vs. DAMPF1). Letter suffixes are used to distinguish signs that are slightly modified but share one meaning and one underlying image (e.g. DAMPF2A vs. DAMPF2B).
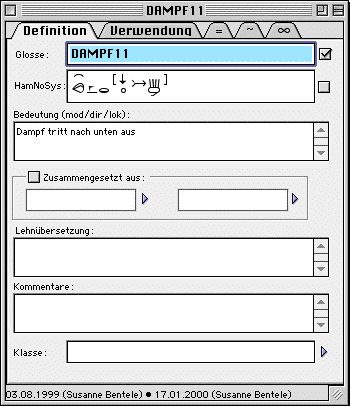
For each sign, you specifiy a gloss as well as a HamNoSys notation. While the gloss is a convenient way of labelling a sign, only the HamNoSys notation enables you to decide whether the form you find is an occurrence of that sign. In addition, the sign window (titled by the gloss, e.g. "DAMPF11")) has fields for describing the meaning in spoken language text, for annotating loan origins and for adding comments. The window also contains references to the constituent signs for non-sequential compounds (e.g. blends) and to sign classes (cf. next paragraph).
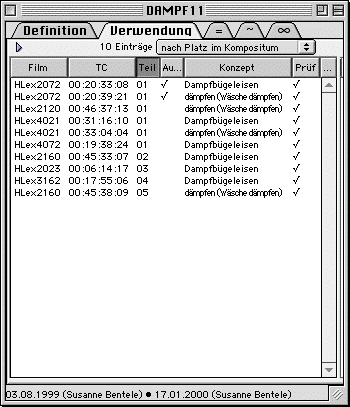
In the second tab for this window ("Verwendung"), you find all occurrences that make use of this particular sign, allowing you to access the occurrences' component structures. In the third and fourth tab, you find cross-references to signs that are equal or similar in form. In the last tab, you find references to signs that use this particular sign as part of a non-sequential compound. (Sequential compounding is modeled by listing the components, see above.)
Much of the information regarding the categorial status of a sign is coded in the sign's gloss. In general, we have two separate categories: productive signs and lexical signs. Dealing with the critical aspect of conventionality of signs and the different meanings, one sign can express in a given context or articulated with a certain mouthing, lexical signs are glossed on two different levels. The following example may help to clarify this point: The GSL-sign FENSTER1 (window) is made by tracing a quadrangle in the air with both index fingers and, normally, by mouthing the German word. This sign is conventionally used to express the meaning "Fenster" (window). The same sign can also be used to denote "Poster" (poster) or "Spiegel" (mirror) in a given context. There is no difference in form and in the underlying image (quadrangle) of these different occurrences of one sign. But FENSTER1is regarded by native signers as a conventional sign with a single meaning "Fenster" (window). Using the same sign to express "Poster" is not considered to be conventional, but it is neither productive in a sense that a specific poster with a certain highth and width is traced in the air. To show this difference with regard to the degree of conventionality of signs – expressing a strong (high degree) or weak association (low degree) between form and meaning – we decided to gloss signs on two different levels.
In our example the sign FENSTER1 (window) is glossed on the level of the sign classes as RECHTECK (quadrangle). This sign class contains all signs that share the same form and the same underlying image (quadrangle). This allows us not to speculate on the degree of meaning differences, e.g. between "Fenster" (window), "Fensterrahmen" (window frame), and "Fensterscheibe" (window glass) in contrast to "Poster" (poster), but to make clear that there is one sign which is conventionally used to express the meaning "Fenster" (window) and other meanings, glossed on the sign level as RECHTECK.
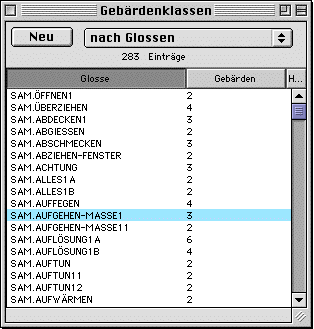
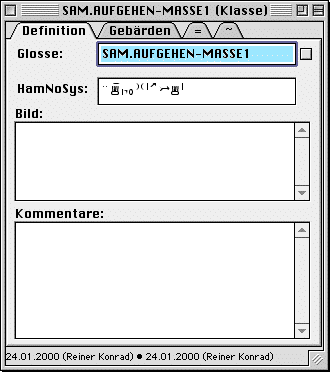
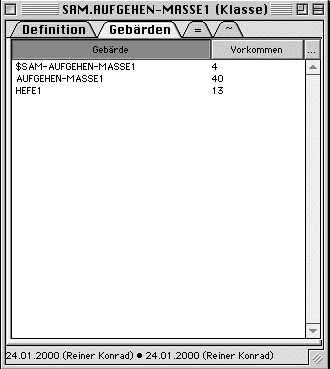
In the sign class window in the first tab ("Definition") each sign is glossed, the form is notated in HamNoSys and the underlying image of the sign is described ("Bild"). Like in other entry windows, you may notate comments. The second tab ("Gebärden") lists all glosses on the sign level and the number of responses which show the sign. In the third and forth tab you find, like in the sign window, cross-references to other signs or sign classes that are equal or similar in form.
Having switched to SQL not only resulted in the speed we needed for this multi-user application. Instead, it also allows us to do special analyses by directly using SQL via programs such as MS Query and to completely link the database to the production processes for both the book and the CD. (In both cases we use Perl programs to produce the output, and we can directly connect to the database from inside the Perl programs.) This should not only result in fewer consistency errors in the final products but also speed up the whole project as we can work on the data up to the final run of the production.
If any research group is interested in trying our approach, we would be happy to provide both the database definition and the front-end. As you might need to do some modifications to cope with the special needs of your project, you would need to have some knowledge of SQL (and RealBasic, if you want to modify the client software as well). And you need the hardware, of course. For the clients, we use Macintosh G3 (the blue ones) equipped with DVD drives as well as G4 machines. (It's not the client program that defines the demands on the hardware, but the video.) The database server is a standard NT server. The machines are networked using a 100BaseT-Switch, once again mainly for performance reasons in accessing video. For any questions, please turn to mailto:Thomas.Hanke@sign-lang.uni-hamburg.de.