In this workshop we are not dealing with large language corpora in general, but specifically with "Lexical Databases", the purpose of which is to register and document a range of vo-cabulary, to serve as an inventory for a language and its dialects, as a source for learning or teaching sign language, as a reference base for analyzing and interpreting sign language sequences, or as a basis for statistical analysis.
We propose to start with an inductive approach: To look at each other´s lexical databases and to decide then what may be relevant to discuss.
Some questions, however, we'll probably have to discuss immediately after having demonstrated different approaches and analysed the structure of different lexical databases and before we enter into a discussion about single phenomena of incompatibility. These questions are:
S. Conlon, M. Evens, T. Ahlswede, and R. Strutz, "Developing a Large Lexical Database for Information Retrieval, Parsing, and Text Generation Systems", Information Processing and Management, vol. 29, no. 1, pp. 1-17, 1993.
A comparison with spoken language databases might be helpful. Those have following purposes (can we adopt the same functionalities?):
(see the extensive documentation about lexical databases, lexica, and dictionaries from the EAGLES project)
Some of these functions probably we do not (yet) have in mind, but maybe one day. The consequences of these functions are obvious:
Similar thoughts apply when we throw a glimpse on the structure of spoken language databases (from the same source):
What is the content of spoken language databases normally? (from the same source):
How would we define the content of sign language LDs? What are for us lexical units (stems, prefixes, compund signs, merged signs, inflected signs, other types of sign formation, idioms)? How do we define lemmata? etc.
There are several databases for sign language existing in Europe. They have reached different stages of development, they represent a different approach to sign language research, they aim at a different purpose (dictionary, research data, teaching material).
The problem is not so much that a different amount of information is registered, i.e. that some databases register more types of data, others less, the problem is not even that different information at all is registered, but the problem is that the information which is registered is probably registered in a different way.
The problem is that of missing standards for naming variables, unknown standards of data entry, and competing and conflicting methods of data coding, a lack of compatibility.
The advantages of having compatible lexical databases are that
What is the range of problems encountered if we think in terms of the compatibility of the data in different databases? What are the differences between different databases which we would like to compare or make compatible?
The easiest to overcome compatibility problem probably consists in the different record structure and field definitions of different databases. Once the structure has been published and is defined transparently the data needed can be converted to another database which has a different record structure.
The compatibility problem starts with the names and abbreviations uses for the keys or tags in a database (lexical key or identifier), e.g. the name for the country tag, the abbreviation for the country code, the name for the language registered, the abbreviation (acronym) of the sign language name, the identifiers for the sign itself, the notation of handshapes and movements etc.
Thomas Hanke has written a paper for the Signing Books project which illustrates how complex this problem is. He demonstrates it for the apparently trivial aspect of country names and language names. The paper is available at the following address on our server:
He also points out that there are ISO norms existing for country and language codes, and his paper contains the links to WWW addresses where these norms are listed.
The problem of incompatibilities is continued for the data entries. To give some examples:
Some databases may be only verbal, register names and glosses, others contain transcriptions as well. Thus the range of information covered is differently. This is not very problematic, were not the kind and type of information also different which is the case when
Most glossing conventions use special characters, a mixture of alphabetical and graphical symbols.
We have to transform this type of code into 7-bit ASCII code for the computer. This task of converting glossing into a common 7-bit notation is in principle possible and may find a not too difficult solution, whereas the task of converting different transcription notation systems cannot be solved completely.
It could well be that the transcriptions of sign language even if they follow the same notation method are entered in different fields or as strings which are (according to handshapes, movements, references) and cannot easily be reassembled. But this problem is easier to solve than the next one.
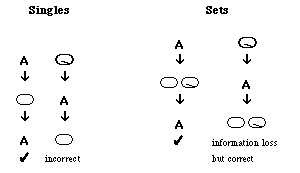
Converting Stokoe to HamNoSys (or HamNoSys to SignPhon) and converting HamNoSys back to Stokoe (or SignPhon back to HamNoSys) leads either to inconsistencies and/or to information loss ("round-trip fidelity problem"). When you convert one notation (e.g. Stokoe or SignPhon) into another (e.g. HamNoSys) and the first knows less symbols for a certain phenomenon to be transcribed than the second it occurs that you have too many choices for converting one symbol into another; if you reverse the procedure and want to regain the first notation from the second this results either in an incorrect solution or an information loss depending how you handle it. The consequences resulting from the irreversibility of the coversion are meant by the term "round-trip fidelity problem".
Simple Example: From Stokoe to HamNoSys (handshape)
Difficult Example: From HamNoSys to SignPhon (shoulder)

Stokoe to HamNoSys and back to Stokoe:
Semantic coding of language data is achieved in numerous, mostly incompatible ways. One well-known procedure is to construct semantic nets.
Homonymy - Synonymy
Morphology - Reduplication
One strategy could be to enter into an agreement upon a common format for new databases and to agree to modify one´s own existing database.
This strategy (a politician´s dream) would once and for all times solve the problem of compatibility both transnationally and for the owner of the individual database
This is the general problem with introducing a standard for data collections when substantial amounts of data have already been collected:
The task of making one´s database compatibel originates for each owner of a database, and the amount of work it needs for each partner to adapt one´s own database to the compatibility criteria could be tremendous.
Such a standard will lack acceptance if, for any group, it turns out to be less powerful than what was used before. The consequence might be a "one fits all"-standard with the danger that for each group far more data has to be entered than they feel necessary.
Another strategy could consist in aggreeing upon a common format as a kind of "database interlingua" and to write programs which could be used for converting automatically national databases into a common European format. The database inter-lingua could consist in its simplest form only a kind of conversion table with reference numbers with no claim to standardize the items registered.
The easiest way to go would be a least common denominator approach. This, however, might turn out to be of little value if some of the coding conventions to be considered are mutually incompatible (cf. round-trip fidelity problem). Furthermore, a solid definition of each of the coding conventions used so far would be necessary in order to define the transformation rules.
The resulting standard would probably not be acceptable (since not powerful enough) for new projects. So, it might be more like a pidgin than a lingua franca.
The task for each owner of a database is easier, and the work load much lower; once the common format has been agreed each partner has only to define the deviations in his or her database but not to modify the existing data entries.
The task of writing a compatibility program for converting existing databases is quite difficult, the work load rests on the shoulders of only one partner; and none of the partners probably has the funds to overtake the responsability for this task.
And achieving compatibility has certain unpleasant consequences: Either a loss of information or a number of incorrect solutions.
How can the two approaches be combined, i. e. is there a coding convention that is powerful enough to be used by each participant for new projects AND serve as an interlingua? One idea might be to define a coding schema as a granularity pyramid, i.e. it is designed as a stack of mutually compatible coding schemes that differ in detailedness. Any actual coding consists of a detailedness specifier and the actual data. A transformation yields in a coding of the highest detailedness that can be achieved taking the source data into account. If two codings from different levels are to be compared, the coding with the higher detailedness is reduced to the level of the other coding.
Another strategy - especially for multilingual databases - might be to resist the temptation to homogenize the entries and work with plain HTML linking instead.
see the paper of Thomas Hanke for country names and language names; it could well be one of our objectives to identify areas in which ISO norms exist for similar phenomena; it is, however, most probably not our aim (and competence) to start to define new ISO norms.
it may well be our aim to standardize data registry out of an linguistic view point in order to reach the same level of standardization for sign languages which is existing for verbal and oral languages (e.g. IPA).
even if we would not intend to reach a level of standardization, it should well be our aim to define conventions enabling us to achieve certain pragmatic goals for instance to initiate comparative linguistic research (e.g. contrastive grammar, sign language statistics) or in order to develop multilingual applications for teaching and learning sign language.
Thomas.Hanke (at) sign-lang.uni-hamburg.de - Rolf.Schulmeister (at) sign-lang.uni-hamburg.de